
type
status
date
slug
summary
tags
category
icon
password
一·、什么是索引
官方定义:一种帮助mysql提高查询效率的数据结构
优点:加快查询速度
缺点:
- 需要额外的空间维护索引
- 增删改要维护索引,速度会变慢
二、索引分类(innodb)
- 主键索引(聚簇索引)
- 设置主键后数据库会自动建立索引
- 单值索引
- 一个索引值包含单个列,一个表可以有很多个单列索引
- 唯一索引
- 索引列值必须唯一,允许有空值,但只允许有一个
- 复合索引
- 一个索引包含多个列
三、创建索引
四、如何使用
- 在主键作为搜索条件的时候,就已经用到了主键索引也就是聚簇索引。
- 而如果使用其他字段作为搜索条件的时候,如果没有构建索引的话,其只能在存储中一个个比对,效率在很多数据的情况下会很差。而当这个字段建立了索引之后,再查询的话,则会用到索引,非簇拥索引。
五、B+树
既然说索引是一种数据结构,那么mysql的索引到底是一个什么样的结构呢?
先说结论,mysql的索引结构是B+树。
那么B+树到底是如何构建的呢?
首先先来看这样的一个情景,在一个表中插入了很多的无序数据。
查询之后会发现,他们是按照id顺序进行的排列。也就是说,在插入之后,数据库对数据进行了排序。为什么要排序呢。

这样存储在数据量大的时候就不方便查询了,于是就引入了分页的概念,相当于把所有的数据来分页管理,而且默认每页的存储16kb。

有了页面,也不方便管理,要查询的时候也不知我需要查询的数据到底在那一页,于是就引入了页面的管理,也就是’页目录‘,在‘页目录’中存放了每一页的主键值和指针,指针指向的就是对于的页。
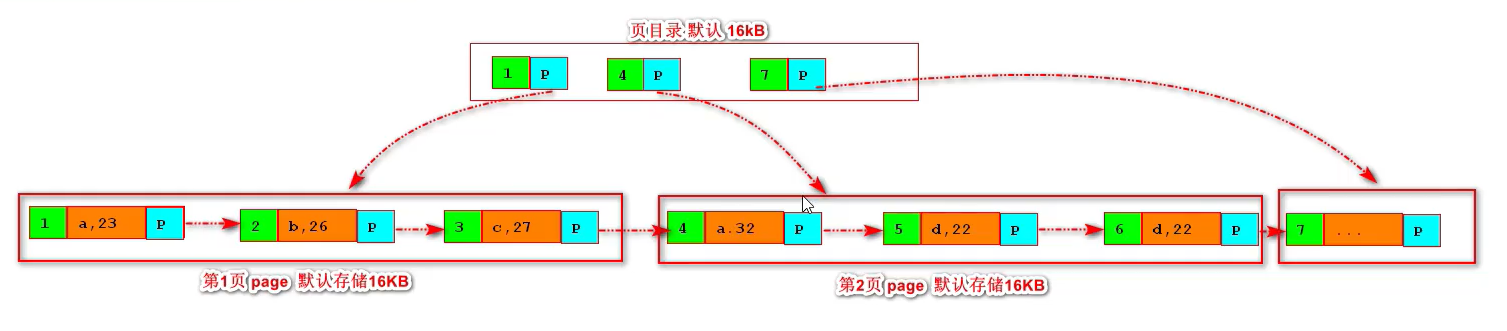
这就是一颗B+树了,当然页目录也有存放大小,当页目录满的时候,就会再多出一层管理页目录的的页目录以此类推(套娃bushi),一般来说3层的这个结果已经可以存放很多数据了。
既然有B+树,那有B树嘛?
有,与B+树大致相同B树与B+树不同的是B树的每个节点都带有数据,
- B+树只有叶节点带有存储的数据,
- B+树所有的叶子节点都有一个链指针
- 数据记录都存放在页节点中的
六、聚簇索引与非聚簇索引
前面一直在提到主键是聚簇索引,到底什么是聚簇索引
- 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
- 非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
非聚簇索引总是二次查找,首先非聚簇索引需要查找主键值,再拿到簇拥索引中再寻找。
那么为什么这里不存放数据直接的地址值呢?
是因为,如果数据发送增删改的话,其中的数据地址需要发生改变,而如果存放的是数据地址则需要花很多资源去维护非聚簇索引。(innodb)
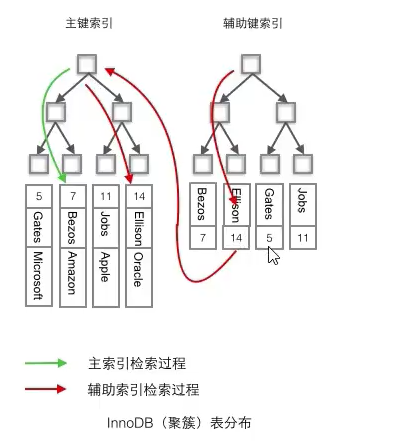
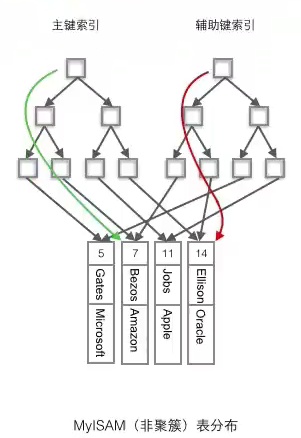
聚簇索引需要注意什么?
主键尽量不要用uuid,太过离散,维护会消耗资源,尽量使用int这类的自增id,雪花算法生成的id
什么情况下不能使用索引?

- Author:内河大魔王
- URL:https://ltyzqhh.top/article/mysql_index
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!